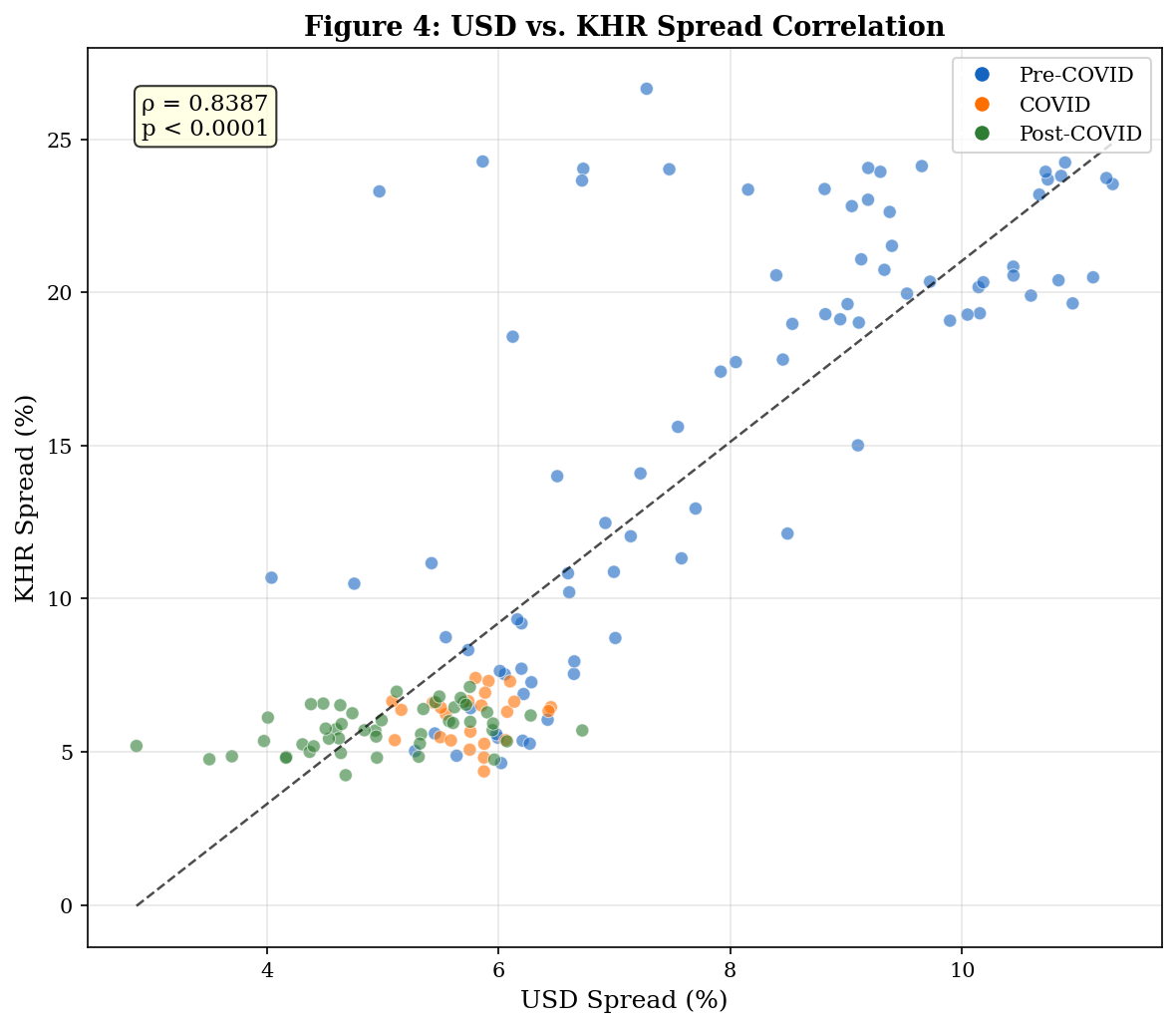
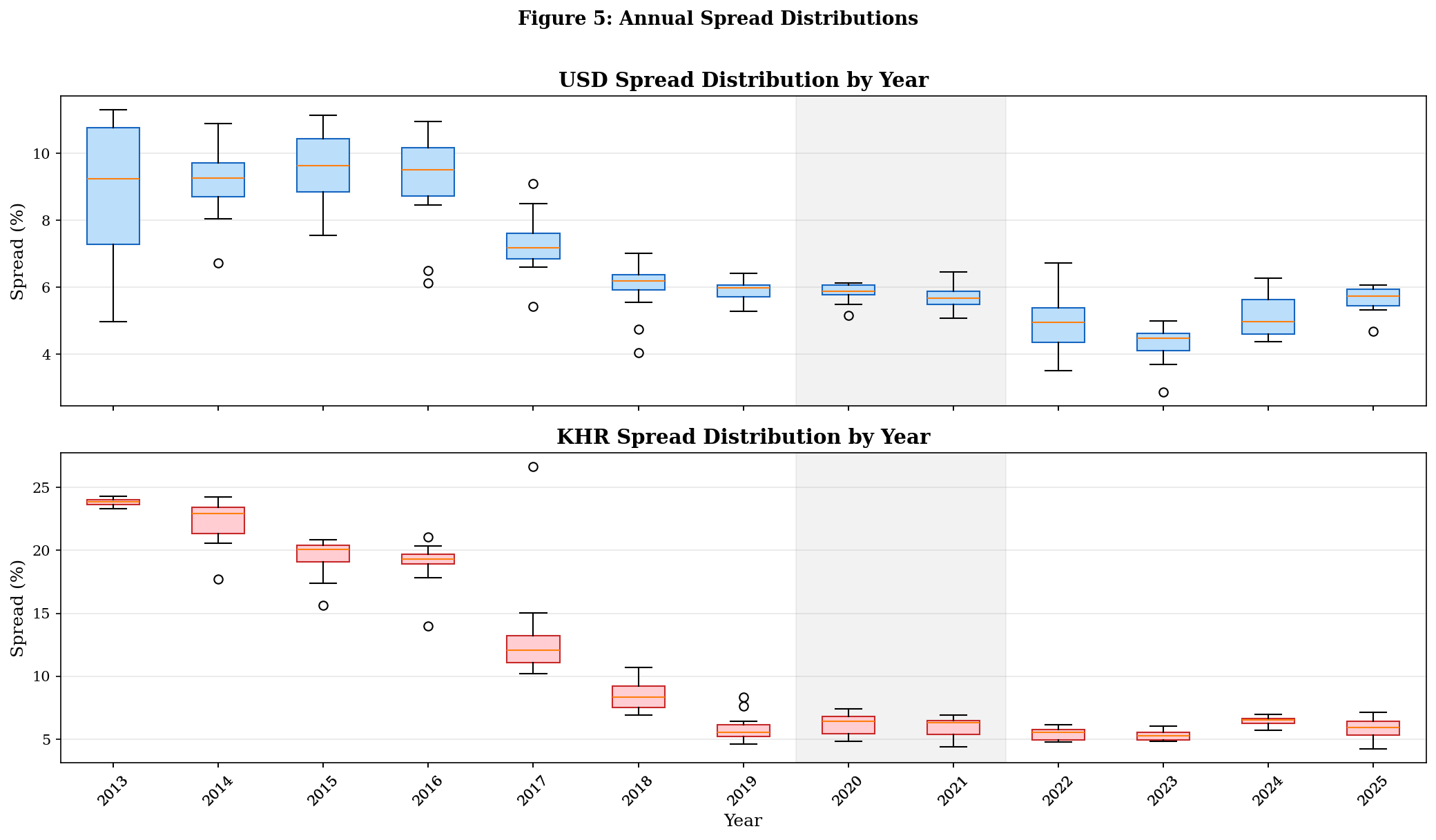
# ─── FIGURE 4: Scatter Plot ──────────────────────────────────────────────────
fig, ax = plt.subplots(figsize=(8, 7))
# Color by period
colors = []
for d in spreads.index:
if d < pd.Timestamp('2020-01-01'):
colors.append('#1565C0')
elif d < pd.Timestamp('2022-01-01'):
colors.append('#FF6F00')
else:
colors.append('#2E7D32')
scatter = ax.scatter(spreads['USD_Spread'], spreads['KHR_Spread'],
c=colors, alpha=0.6, s=40, edgecolors='white', linewidth=0.5)
# Regression line
slope, intercept, r_value, p_value, std_err = stats.linregress(
spreads['USD_Spread'], spreads['KHR_Spread'])
x_line = np.linspace(spreads['USD_Spread'].min(), spreads['USD_Spread'].max(), 100)
ax.plot(x_line, slope * x_line + intercept, 'k--', linewidth=1.2, alpha=0.7)
# Legend
from matplotlib.lines import Line2D
legend_elements = [
Line2D([0], [0], marker='o', color='w', markerfacecolor='#1565C0', markersize=8, label='Pre-COVID'),
Line2D([0], [0], marker='o', color='w', markerfacecolor='#FF6F00', markersize=8, label='COVID'),
Line2D([0], [0], marker='o', color='w', markerfacecolor='#2E7D32', markersize=8, label='Post-COVID'),
]
ax.legend(handles=legend_elements, loc='upper right')
ax.set_xlabel('USD Spread (%)')
ax.set_ylabel('KHR Spread (%)')
ax.set_title('Figure 4: USD vs. KHR Spread Correlation', fontweight='bold', fontsize=13)
ax.text(0.05, 0.95, f'ρ = {r_value:.4f}\np < 0.0001',
transform=ax.transAxes, fontsize=11, verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='lightyellow', alpha=0.8))
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('../figures/fig4_correlation.png', dpi=300, bbox_inches='tight')
plt.show()
print('Saved: fig4_correlation.png')