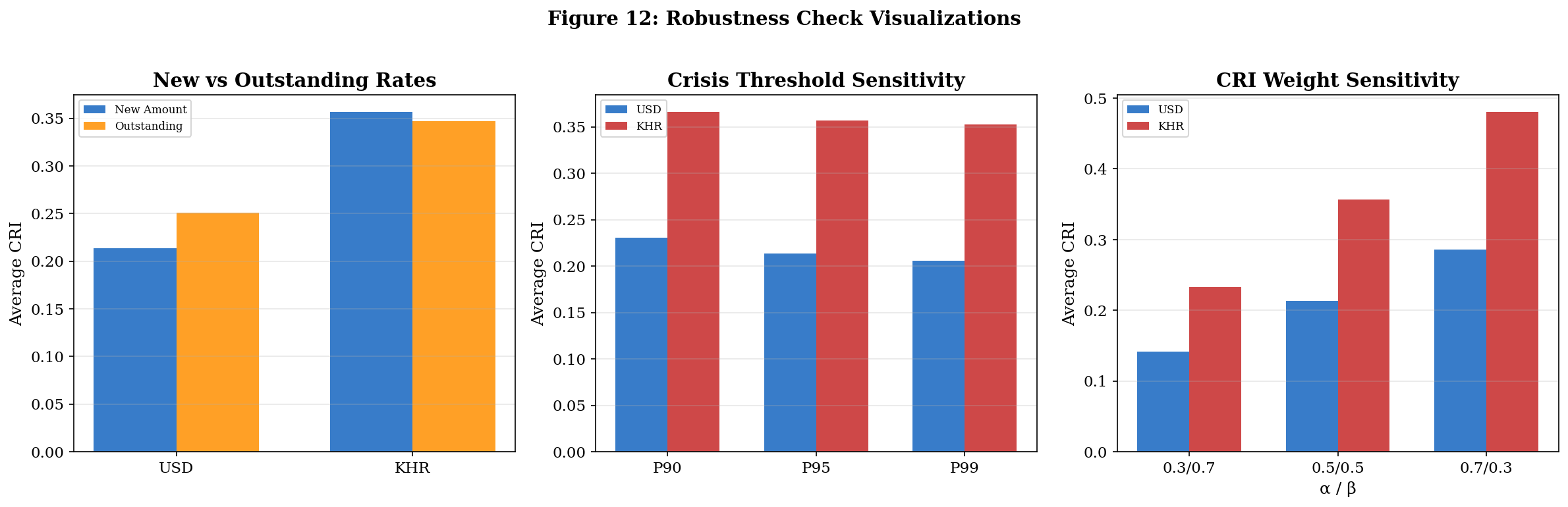
# ─── FIGURE 12: Robustness Comparison ────────────────────────────────────────
fig, axes = plt.subplots(1, 3, figsize=(16, 5))
w = 0.35
# Panel 1: New vs Outstanding
ax = axes[0]
x = np.arange(2)
ax.bar(x - w/2, [cri_usd_base, cri_khr_base], w, label='New Amount', color='#1565C0', alpha=0.85)
ax.bar(x + w/2, [cri_usd_out, cri_khr_out], w, label='Outstanding', color='#FF8F00', alpha=0.85)
ax.set_xticks(x); ax.set_xticklabels(['USD', 'KHR'])
ax.set_title('New vs Outstanding Rates', fontweight='bold')
ax.set_ylabel('Average CRI'); ax.legend(fontsize=8); ax.grid(True, alpha=0.3, axis='y')
# Panel 2: Threshold sensitivity
ax = axes[1]
x = np.arange(3)
ax.bar(x - w/2, [r['CRI_USD'] for r in threshold_results], w, label='USD', color='#1565C0', alpha=0.85)
ax.bar(x + w/2, [r['CRI_KHR'] for r in threshold_results], w, label='KHR', color='#C62828', alpha=0.85)
ax.set_xticks(x); ax.set_xticklabels([f'P{p}' for p in [90,95,99]])
ax.set_title('Crisis Threshold Sensitivity', fontweight='bold')
ax.set_ylabel('Average CRI'); ax.legend(fontsize=8); ax.grid(True, alpha=0.3, axis='y')
# Panel 3: CRI weight sensitivity
ax = axes[2]
x = np.arange(3)
ax.bar(x - w/2, [weight_results[1]['CRI_USD'], weight_results[0]['CRI_USD'], weight_results[2]['CRI_USD']],
w, label='USD', color='#1565C0', alpha=0.85)
ax.bar(x + w/2, [weight_results[1]['CRI_KHR'], weight_results[0]['CRI_KHR'], weight_results[2]['CRI_KHR']],
w, label='KHR', color='#C62828', alpha=0.85)
ax.set_xticks(x); ax.set_xticklabels(['0.3/0.7', '0.5/0.5', '0.7/0.3'])
ax.set_xlabel('α / β')
ax.set_title('CRI Weight Sensitivity', fontweight='bold')
ax.set_ylabel('Average CRI'); ax.legend(fontsize=8); ax.grid(True, alpha=0.3, axis='y')
fig.suptitle('Figure 12: Robustness Check Visualizations', fontweight='bold', fontsize=14, y=1.02)
plt.tight_layout()
plt.savefig('../figures/fig12_robustness.png', dpi=300, bbox_inches='tight')
plt.show()
print('Saved: fig12_robustness.png')